Artem ZholusI am a third year PhD student in MILA and Polytechnique Montréal supervised by Prof. Sarath Chandar. Besides that, I am a visiting researcher at FAIR @ Meta advised by Mido Assran. My ultimate research goal is to build adaptive and autonomous agents that solve open-ended tasks. To step towards this goal, I use Language and World Models, Structured Communication, and (Distributed) Reinforcement Learning. 👉 Expand to see what I mean by each of these ideas
My current research project focuses on scaling world models. My past research covered Model-based Reinforcement Learning via World Models, interactive learning of embodied agents, and boosting in-context memory of Model-based RL agents. Also, I spent some time in ML industry working as an ML Engineer doing drug discovery with RL and Language Models. Previously I was a student researcher at Google DeepMind with Ross Goroshin. Also, I had two internships at EPFL: at the LIONS lab (in RL theory) under Prof. Volkan Cevher and at VILAB (in Multimodal Representation Learning) under Prof. Amir Zamir. I obtained my Masters degree at MIPT studying AI, ML, and Cognitive Sciences and working at the CDS lab under Prof. Aleksandr Panov on task generalization in model-based reinforcement learning. I received my BSc degree from ITMO University majoring in Computer Science and Applied Mathematics. |

|
News
|
Papers |

|
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and PlanningMido Assran*, Adrien Bardes*, David Fan*, Quentin Garrido*, Russell Howes*, Mojtaba Komeili*, Matthew Muckley*, Ammar Rizvi*, Claire Roberts*, Koustuv Sinha*, Artem Zholus*, Sergio Arnaud*, Abha Gejji*, Ada Martin*, Francois Robert Hogan*, Daniel Dugas*, Piotr Bojanowski, Vasil Khalidov, Patrick Labatut, Francisco Massa, Marc Szafraniec, Kapil Krishnakumar, Yong Li, Xiaodong Ma, Sarath Chandar, Franziska Meier*, Yann LeCun*, Michael Rabbat*, and Nicolas Ballas* Technical Report, 2025 website / arxiv / code / blogpost / hugginface / By scaling world model pretraining to over a million hours of internet videos, we build V-JEPA 2 that excels at motion understanding, human-action anticipation, and video question answering. We show how action-conditioned post training on just 62 hours of unlabeled robot videos, enables zero-shot generalization in robotic control through planning in the latent space for tasks such as pick-and-place. |
|
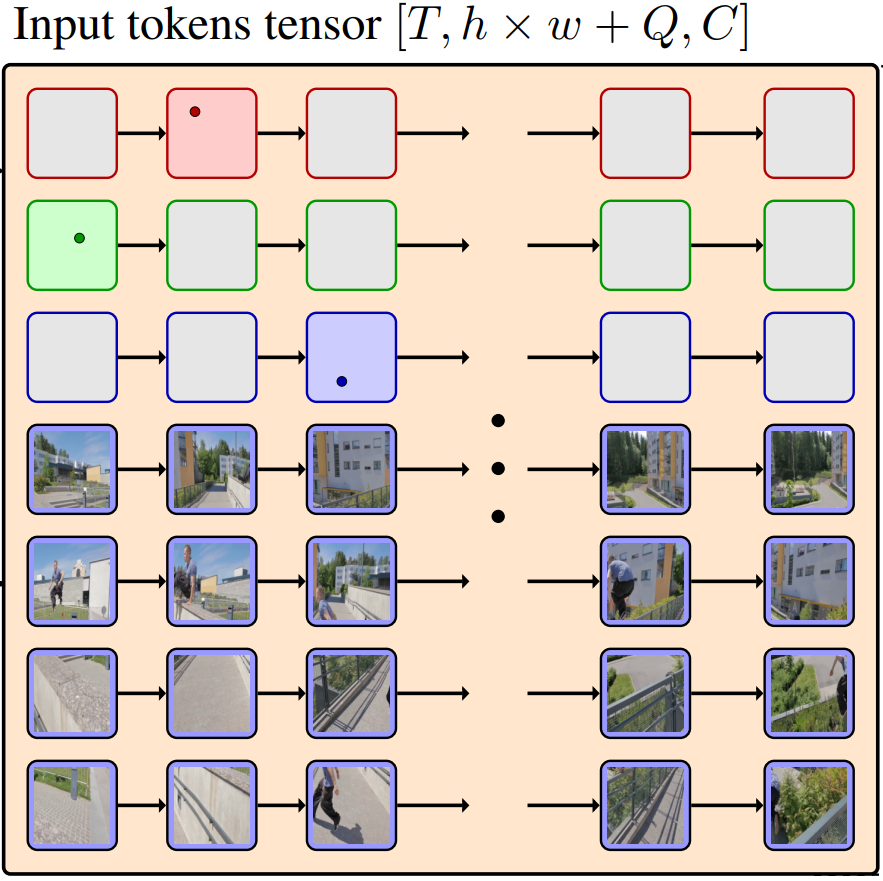
TAPNext: Tracking Any Point (TAP) as Next Token PredictionArtem Zholus, Carl Doersch, Yi Yang, Skanda Koppula, Viorica Patraucean, Xu Owen He, Ignacio Rocco, Mehdi S. M. Sajjadi, Sarath Chandar, Ross Goroshin ICCV, 2025 website / arxiv / video / code / A new model for the Point Tracking task. Achieves SOTA with a huge margin while offering significantly faster online inference. We use a drastically different (from anything existing before for this task) approach, showing that only the scale of compute and data matters for this task. |

|
BindGPT: A Scalable Framework for 3D Molecular Design via Language Modeling and Reinforcement LearningArtem Zholus, Maksim Kuznetsov, Roman Schutski, Rim Shayakhmetov, Daniil Polykovskiy, Sarath Chandar, Alex Zhavoronkov AAAI with Best Poster Award, 2025 website / arxiv / video / hugginface / BindGPT is a new framework for building drug discovery models that leverages compute-efficient pretraining, supervised funetuning, prompting, reinforcement learning, and tool use of LMs. This allows BindGPT to build a single pre-trained model that exhibits state-of-the-art performance in 3D Molecule Generation, 3D Conformer Generation, Pocket-Conditioned 3D Molecule Generation, posing them as downstream tasks for a pretrained model, while previous methods build task-specialized models without task transfer abilities. |

|
Mastering Memory Tasks with World ModelsMohammad Reza Samsami*, Artem Zholus*, Janarthanan Rajendran, Sarath Chandar ICLR with oral (top-1.2% of accepted papers), 2024 website / arxiv / openreview / code / The new State-of-the-Art performance in a diverse set of memory-intense Reinforcement Learning domains: bsuite (tabular, low dimensional), POPgym (tabular, high dimensional), Memory Maze (3D, embodied, high dimensional, long-term). Importantly, we reach super-human performance in Memory-Maze! |

|
IGLU Gridworld: Simple and Fast Environment for Embodied Dialog AgentsArtem Zholus, Alexey Skrynnik, Shrestha Mohanty, Zoya Volovikova, Julia Kiseleva, Artur Szlam, Marc-Alexandre Coté, Aleksandr I. Panov Embodied AI workshop @ CVPR, 2022 arxiv / code / slides / A lightweight reinforcement learning environment for building embodied agents with language context tasked to build 3D structures in Minecraft-like world. |

|
IGLU 2022: Interactive Grounded Language Understanding in a Collaborative Environment at NeurIPS 2022Julia Kiseleva*, Alexey Skrynni*, Artem Zholus*, Shrestha Mohanty*, Negar Arabzadeh*, Marc-Alexandre Côté*, Mohammad Aliannejadi, Milagro Teruel, Ziming Li, Mikhail Burtsev, Maartje ter Hoeve, Zoya Volovikova, Aleksandr Panov, Yuxuan Sun, Kavya Srinet, Arthur Szlam, Ahmed Awadallah NeurIPS, Competition Track, 2022 website / arxiv / code / AI competition where the goal is to follow a language instruction with context while being embodied in a 3D blocks world (RL track) and to ask a clarifying question in the case of ambiguity (NLP track). |
|
Factorized World Models for Learning Causal RelationshipsArtem Zholus, Yaroslav Ivchenkov, and Aleksandr Panov OSC workshop, ICLR, 2022 arxiv / code / An RL agent that can generalize behavior on unseen tasks, which is done by learning a structured world model and constraining task specific information. |
|
Design and source code from Jon Barron's website |